A lattice is the set (a discrete subgroup) of all integer combinations of some vectors ({\vec{v_1}, \ldots, \vec{v_k}} \in \mathbb{R}^n), (L = { a_1 \cdot \vec{v_1} + \cdots + a_k \cdot \vec{v_k} | a_i \in \mathbb{Z} } \subset \mathbb{R}^n ). We can call the set ({v_1, \ldots, v_k}) a basis of (L)
A given lattice, (L), may have an infinite number of distinct bases. However, the volume of their fundamental shape is an invariant, the determinant of the lattice (which can be found by taking the determinant of a basis for the lattice).
[1 0 0 0]
[0 1 0 0]
[0 0 1 0]
[0 0 0 1]
[-2]
[-6]
[ 4]
[-6]
[ -7 -26 -158 172]
[ -4 -15 -91 99]
[ -1 -7 -38 39]
[ 1 9 44 -40]
[-1378]
[-2516]
[ 904]
[ 394]
True
Notice that with a "nice" basis for (L) the weights which produce (v \in L) are going to be close to the size of (v). With a bad basis our weights were very large for such a small vector.
A good question to ask about a lattice: What is the shortest vector?
Given only a generic basis, this is an NP-hard problem
LLL (Lenstra, Lenstra, Lovasz) is a polynomial time algorithm which takes a basis for a lattice, and gives a "reduced" basis. The reduced basis gives an approximate solution to the shortest vector problem (SVP) and then some.
[ 6765 267914296 0]
[ 10946 102334155 0]
[ 17711 165580141 1]
[ -1 -6765 6765]
[ 0 -4181 -10946]
[ 21892 0 1]
[ -1 -6765 6765]
[ -1 -10946 -4181]
[ 21892 0 1]
[ 0 -10946 6765]
[ 0 6765 -4181]
[ -1 1 1]
If you want to start proving things related to LLL you'll want to know a bit more:
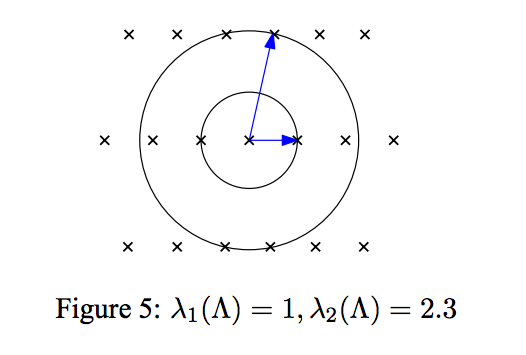
Note that the successive minima are an invariant of the lattice. They represent the best theoretical basis (although it might not be achievable as the dimension grows).
A reduced basis, (\vec{b_1}, \ldots, \vec{b_d}), will have lengths which approximate the successive minima. Depending on the algorithm there is an approximation factor, (\alpha \approx \sqrt{4/3}), such that:
AND
Note that (\parallel \vec{b_i^{*}} \parallel) is the length of the (i^{\textrm{th}}) Gram-Schmidt vector. So:
A reduced basis has the property that the Gram-Schmidt lengths "cannot drop too fast" which is captured by:
As an LLL researcher my particular flavor is to attack applications by changing the underlying lattice so that there is a big gap between (\lambda_i). That way an approximation will be enough.
A lattice is the set (a discrete subgroup) of all integer combinations of some vectors ({\vec{v_1}, \ldots, \vec{v_k}} \in \mathbb{R}^n), (L = { a_1 \cdot \vec{v_1} + \cdots + a_k \cdot \vec{v_k} | a_i \in \mathbb{Z} } \subset \mathbb{R}^n ). We can call the set ({v_1, \ldots, v_k}) a basis of (L)
A given lattice, (L), may have an infinite number of distinct bases. However, the volume of their fundamental shape is an invariant, the determinant of the lattice (which can be found by taking the determinant of a basis for the lattice).
[1 0 0 0]
[0 1 0 0]
[0 0 1 0]
[0 0 0 1]
[-2]
[-6]
[ 4]
[-6]
[ -7 -26 -158 172]
[ -4 -15 -91 99]
[ -1 -7 -38 39]
[ 1 9 44 -40]
[-1378]
[-2516]
[ 904]
[ 394]
True
Notice that with a "nice" basis for (L) the weights which produce (v \in L) are going to be close to the size of (v). With a bad basis our weights were very large for such a small vector.
A good question to ask about a lattice: What is the shortest vector?
Given only a generic basis, this is an NP-hard problem
LLL (Lenstra, Lenstra, Lovasz) is a polynomial time algorithm which takes a basis for a lattice, and gives a "reduced" basis. The reduced basis gives an approximate solution to the shortest vector problem (SVP) and then some.
[ 6765 267914296 0]
[ 10946 102334155 0]
[ 17711 165580141 1]
[ -1 -6765 6765]
[ 0 -4181 -10946]
[ 21892 0 1]
[ -1 -6765 6765]
[ -1 -10946 -4181]
[ 21892 0 1]
[ 0 -10946 6765]
[ 0 6765 -4181]
[ -1 1 1]