Read CSV
K-means
K-means clustering is a clustering method that aims to partition N observations into K clusters in which each observation belongs to the cluster with the nearest cluster center (cluster centroid).
The standard k-means algorithm is only applicable to numeric data and isn't directly applicable to categorical data for various reasons.
One being that as the sample space for categorical data is discrete, an Euclidean distance function on such a space is not meaningful.
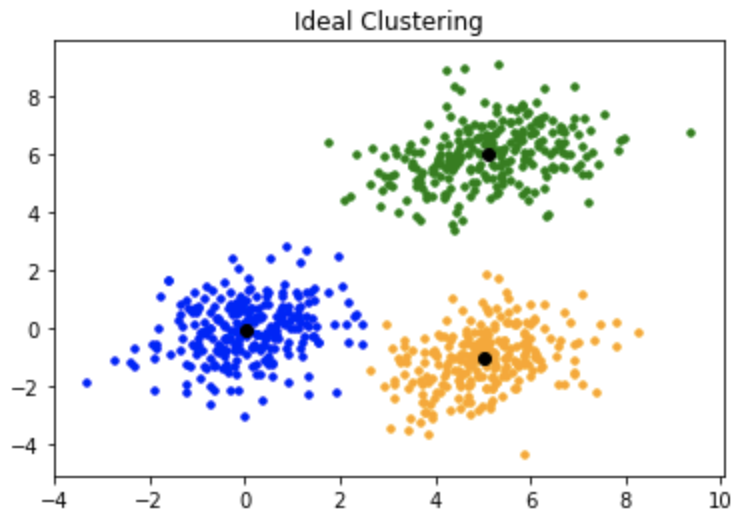
How does it work ?
If we would be given the centroids we would assign each observation to to the centroid that is closest.
But since we aren't given the centroids' locations, we start by placing the centroids randomly in the feature space and labelling the observations (assigning them to the closest centroid).
Then we update the locations of the centroids and label the observations again. And we repeat this procedure as many times as needed until the centroids stop moving.

| imdb_title_id | title | original_title | year | date_published | genre | duration | country | language | director | ... | actors | description | avg_vote | votes | budget | usa_gross_income | worlwide_gross_income | metascore | reviews_from_users | reviews_from_critics | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | tt0000574 | The Story of the Kelly Gang | The Story of the Kelly Gang | 1906 | 1906-12-26 | Biography, Crime, Drama | 70 | Australia | NaN | Charles Tait | ... | Elizabeth Tait, John Tait, Norman Campbell, Be... | True story of notorious Australian outlaw Ned ... | 6.1 | 537 | $ 2250 | NaN | NaN | NaN | 7.0 | 7.0 |
| 1 | tt0001892 | Den sorte drøm | Den sorte drøm | 1911 | 1911-08-19 | Drama | 53 | Germany, Denmark | NaN | Urban Gad | ... | Asta Nielsen, Valdemar Psilander, Gunnar Helse... | Two men of high rank are both wooing the beaut... | 5.9 | 171 | NaN | NaN | NaN | NaN | 4.0 | 2.0 |
2 rows × 22 columns
Let's first start with only one feature
Scale the input feature
Since we don't have prior information about this dataset we don't know how to set the number of clusters to best split this data.
We therefore need to find the optimal number of clusters.
For that we can compute the model's inertia which is the mean squared distance between each observation and it's centroid.
By default the Kmeans algorithm runs n times and keeps the model with the lowest inertia.
So theoretically the best number of clusters can be defined by the model that has the lowest inertia right?
Well no as the more clusters we have, the closer each instance will be to it's closest centroid and the lower the inertia will be.
If we would have a number of clusters equal to the number of observations, then the inertia would be 0 and that doesn't help with anything.
So we need to select the number of clusters using the elbow method.

We plot the explained variation as a function of the number of clusters, and pick the elbow of the curve as the number of clusters to use.
Another option to get the best number of clusters is to use a silhouette score. But it's computationally expensive and we'll stick to the elbow method for practical reasons.
Get the best number of clusters based on the elbow method, where the difference between scores is smaller than the 90% percentile.
Let's check the first observation
| duration | |
|---|---|
| count | 81273.000000 |
| mean | 100.565981 |
| std | 25.320189 |
| min | 40.000000 |
| 25% | 88.000000 |
| 50% | 96.000000 |
| 75% | 108.000000 |
| max | 3360.000000 |

